언젠가 누군가 얘기해 줬었죠. 웹 스크래핑의 최고봉은 python이라고. Node.js 가 생기고 jquery를 스크래핑에 쓸 수 있게 된 이후 부터는 그게 아니라고 생각했는데, 오늘 다시 저의 생각을 바꿀만한 녀석이 나왔네요.
2016/02/27 editor’s choice( 234★)
링크 : https://github.com/syrusakbary/gdom
GDOM은 python 으로 만들어진 라이브러리인데, DOM을 해석하는데 사용할 수 있는 라이브러리중 끝판왕이라고 보여집니다.
GraphQL기반으로 되어 있구요.
- 설치 : pip install gdom
- 실행
스크래핑은 먼저 스크래핑을 할 사이트를 먼저 찾아봐야죠.
타겟은 해커뉴스 daily 베스트로 해 보겠습니다.
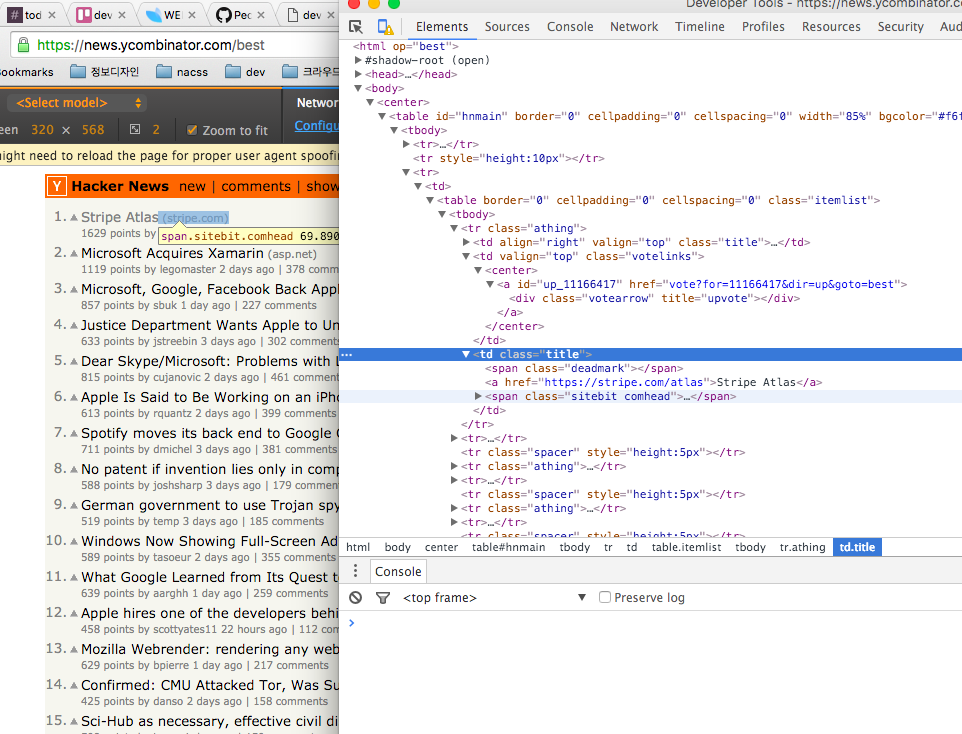
이것을 스크랩하기 위해서 내가 얻고자 하는 JSON형식으로 지정만 해주면 됩니다.
다음과 같이 hn-best.json 파일을 만들어주고
{
page(url:"http://news.ycombinator.com/best") {
items: query(selector:"tr.athing") { //tr 중 athing 클래스 검색해서
rank: text(selector:"td span.rank") //순위
title: text(selector:"td.title a") //타이틀 ...
sitebit: text(selector:"span.comhead a")
url: attr(selector:"td.title a", name:"href")
attrs: next {
score: text(selector:"span.score")
user: text(selector:"a:eq(0)")
comments: text(selector:"a:eq(2)")
}
}
}
}
query 명령어를 통해서 DOM을 검사해서 바로 JSON 값을 얻겠다고 지정해 둡니다.
gdom hn-best \> ouput.json
결과를 output.json 파일로 떨어뜨려 주면 파일로 저장이 됩니다.

이렇게 이쁘게 결과가 떨어짐을 볼 수 있습니다.
By Keen Dev on February 27, 2016.
Exported from Medium on May 31, 2017.